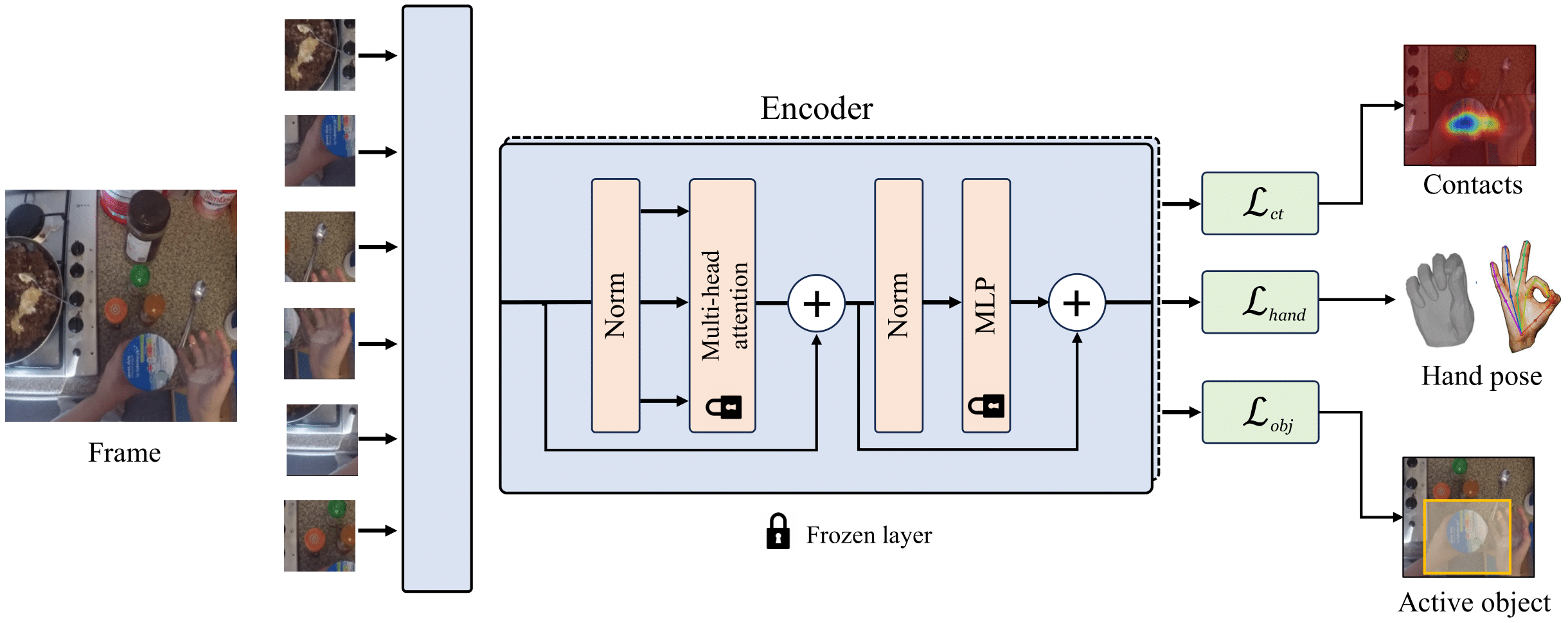
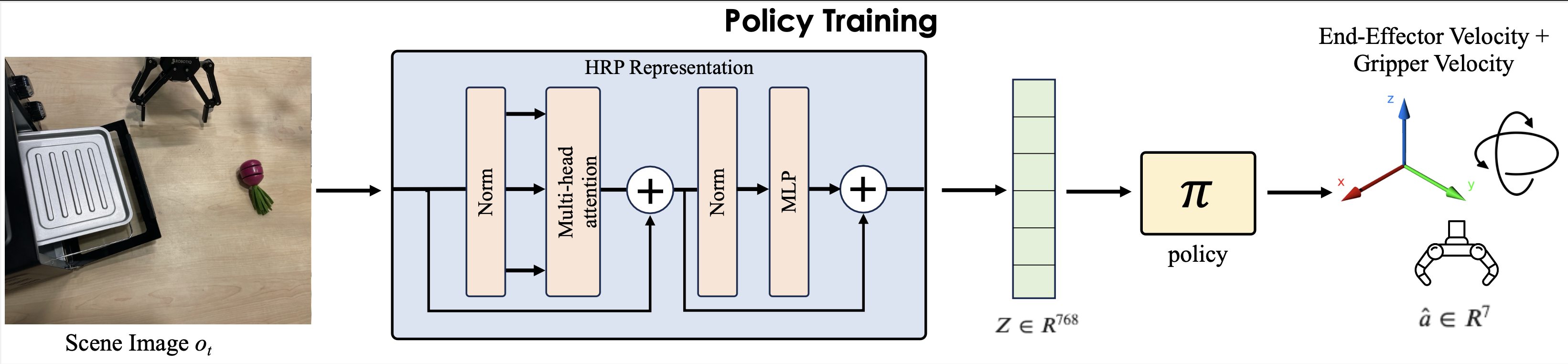
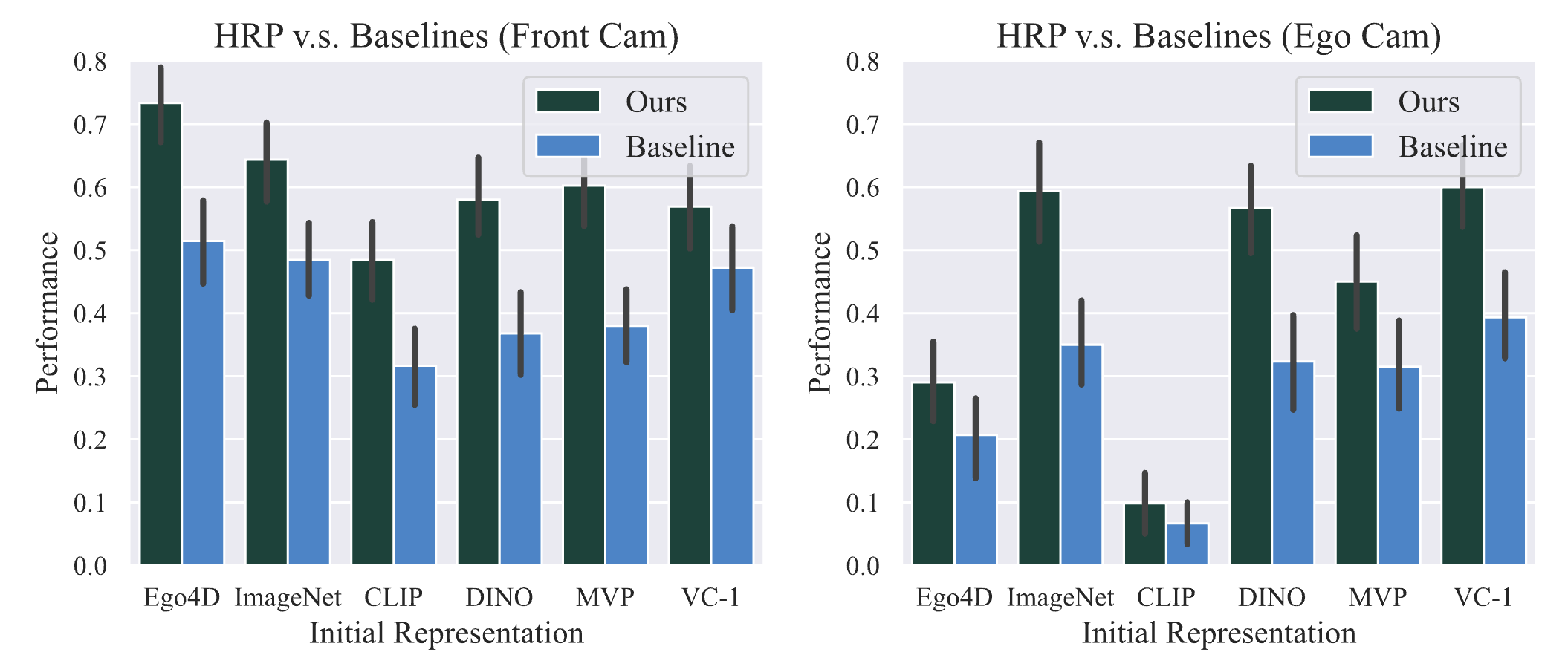
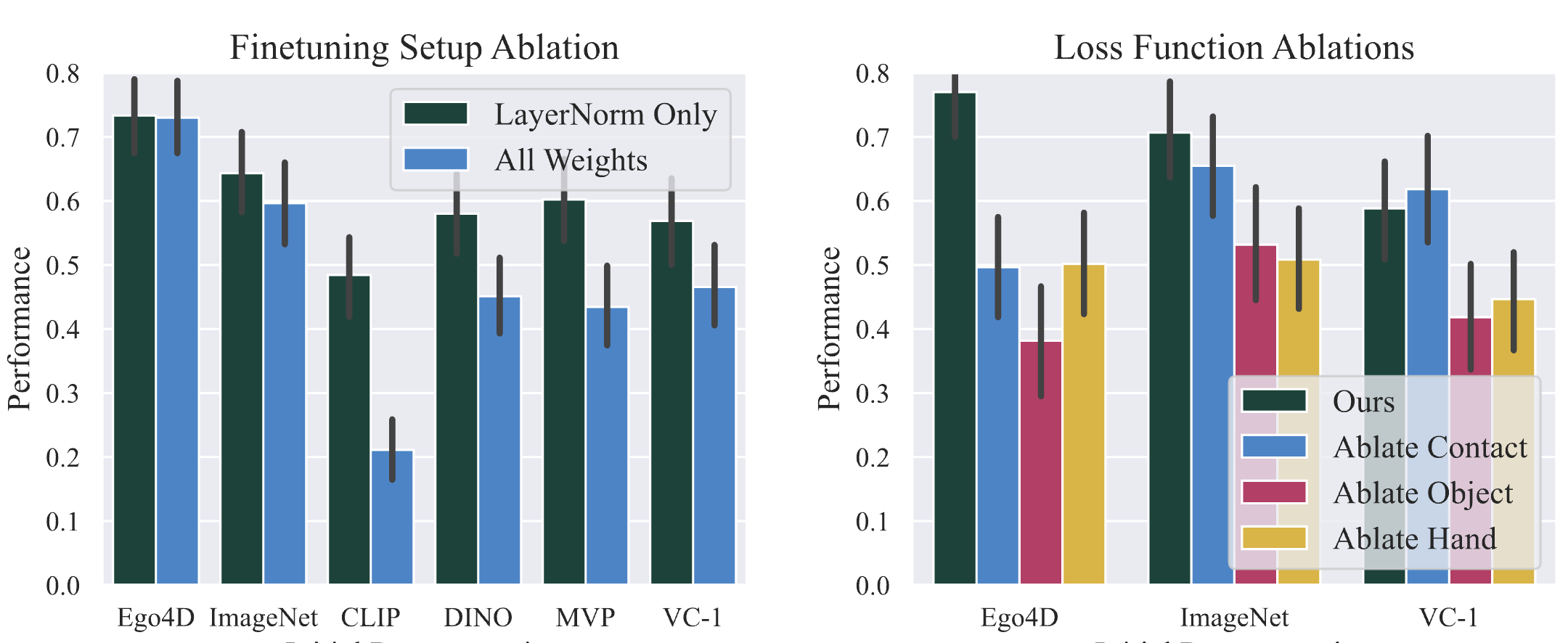
We benchmark HRP on 5 Tasks, 3 robot morphologies
@inproceedings{srirama2024hrp,
title={HRP: Human Affordances for Robotic Pre-Training},
author = {Mohan Kumar Srirama and Sudeep Dasari and Shikhar Bahl and Abhinav Gupta},
booktitle = {Proceedings of Robotics: Science and Systems},
address = {Delft, Netherlands},
year = {2024},
}